Running a Fully Automated Media Server

No Plex Zone
8 years ago I started No Plex Zone. It was a great foray into building my own home lab and learning Linux. I initially just wanted to watch movies and shows in my college campus, and before long my friends asked me if they could also watch stuff on my Plex server too. I happily obliged and manually grabbed new releases when asked. This process quickly became unsustainable. The community around Plex grew significantly since then, with many great tools available to host a fully automated media server. This was written with the focus of explaining to friends how my media server works.
No Cloud Zone
Everything is now hosted in a data center. The 10mbps upload in my new apartment rendered streaming completely useless outside of my home network (thanks Spectrum). Sadly I couldn’t continue my home lab for this project, but I placated myself with a new shiny dedicated server with 1gbps uplink and Google Drive as a storage backend.
Automation
User Flow
Before diving into all the moving pieces, this is what the user experience looks like. If a movie or show is not available on Plex, there are two interfaces to request new media:
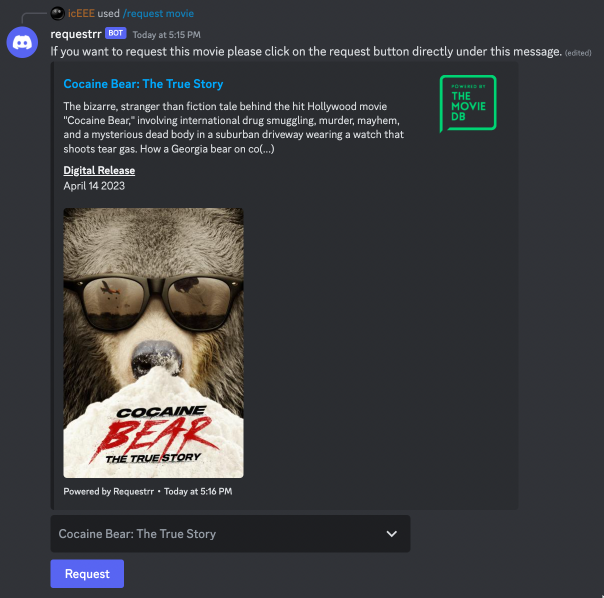
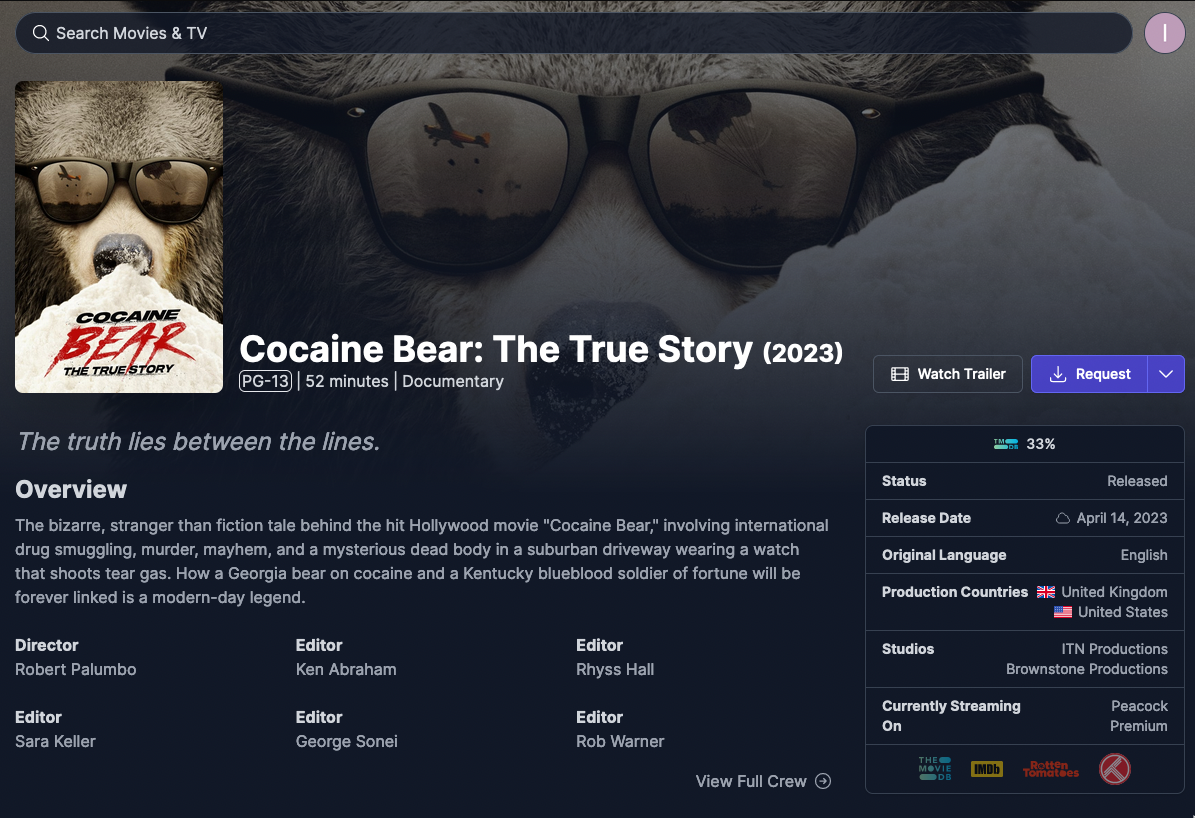
If the requested media does not exist, it will be automatically downloaded when available and notify the requester. There are no manual steps other than deciding what to watch and hitting a button. Automation achieved!
If the requested media does not exist, it will be downloaded when available and notify the requester via Discord. Automation achieved!
Core Infrastructure
No Plex Zone was originally installed and configured by manually running commands. Since I was learning Linux and didn’t document anything, it was hard to manage and make changes. All software was run by connecting to the machine and manually executing the startup command. Now everything is documented in code and does not require direct ssh access to make any changes.
Server Management
- Ansible: Provision the server with core OS dependencies, container orchestration software (Nomad), networking tweaks, and mount paths for Google Drive via UnionFS.
- Nomad: Deploys and manages every other piece of software.
- Duplicacy: Automatic backups of stateful containers. This includes local application configurations and databases.
- Prometheus: Collect metrics.
- Loki: Aggregate all logs.
- Vector: Formats and routes logs and metrics.
- Grafana: Visualises metrics and logs.
- Uptime Kuma: Simple monitoring to alert when an application is down.
Web
- Traefik: Reverse proxy with automatic container discovery with Nomad to allow external traffic to access exposed applications.
- Authelia: Single Sign-On and authentication for applications.
- CloudFlare: Assigns domain names for each web app, provides full HTTPS, and a CDN for better peering.
Media Servers
- Plex: Serves movies, TV shows, and music.
- Kavita: Serves eBooks.
Media Automation
The *Arr stack is the heart of the automation process. This software suite is designed to be a one stop solution to automatically monitor, grab, sort, orgranise, and import media. When a request is sent from the Discord bot (Requestrr) or the web request frontend (Overseerr), it is routed to one of the following:
- Radarr: Movies.
- Sonarr: TV.
- Readarr: Books.
- Lidarr: Music.
Other:
- Prowlarr: Indexer management.
- Autobrr: Additional download monitoring and filtering.
Prowlarr is used to add, configure, and sync indexers to the appropriate member of the *Arr stack for effective searching of wanted media.
Say a user requests “Cocaine Bear (2023)” from either Requestrr or Overseerr. The request is then sent to Radarr. Radarr will then monitor the movie and start a search across the indexers configured by Prowlarr and return a list of potential results.
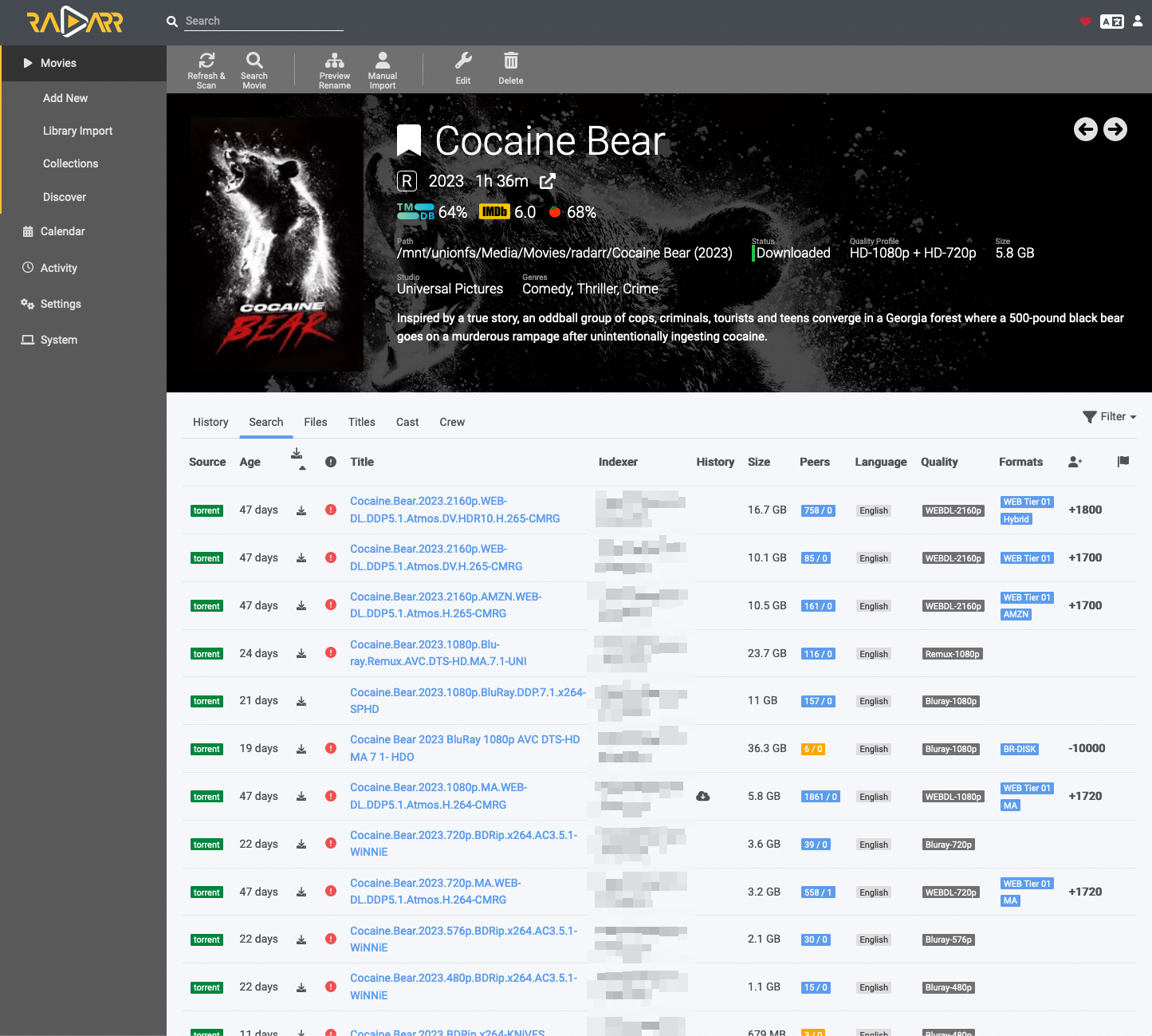
Radarr is configured to score results based on a set of parameters. In this case, a 1080p release was requested. Other resolutions are ignored, and the quality is used to determine the most apt release to automatically grab. These scores are managed by the person who created TRaSH-Guides. The creator provides an excellent guide on how to pick a suitable profile and information on how releases are scored.


By default, Radarr and the rest of the *Arr stack are configured to query RSS feeds from indexers at specific intervals (eg. every 15 minutes) to see if any new uploads match monitored releases. Autobrr is an auxillary application that directly monitors indexer IRC channels instead, where new uploads are announced immediately. Once an upload is announced, it will parse the string and filter accordingly before sending a notification to the appropriate *Arr application. This is particularly useful for grabbing the latest TV shows as soon as they finish airing.


Cloud Sync and Playback
Hosting media on Google Drive has its drawbacks. There is a cap on how much can be uploaded in one day and API limits. Getting rate limited by the API results in noticeable degradation in viewing experience, such as stuttering and frequent pauses. Several tools are used to ensure we abide by Google’s limitations and have smooth video playback.
- Rclone: Mount Google Drive locally and sync local contents to remote storage.
- Autoscan: Notifies Plex once new media is available.
- Cloudplow: Pushes locally downloaded content to Google Drive.
- UnionFS: Overlays multiple directories into one mount point.
Once media is grabbed by the *Arr stack, the file will be organised into a and renamed to match metadata provided by sources such as TVDB and the file quality.
Original Path: /mnt/unionfs/downloads/radarr
Original Filename: Cocaine.Bear.2023.1080p.MA.WEB-DL.DDP5.1.Atmos.H.264-CMRG
New Path: /mnt/unionfs/Media/Movies/radarr/Cocaine Bear (2023)
New Filename: Cocaine Bear (2023) {imdb-tt14209916} [WEBDL-1080p][EAC3 Atmos 5.1][x264]-CMRG.mkv
When a file is downloaded and processed for organisation (imported), it will be
placed in /mnt/local/Media, which resides on the machine’s local hard drive.
Google Drive is mounted to /mnt/local/Media using Rclone. UnionFS is used to
overlay both directories into /mnt/unionfs/Media. This way media located
locally and remotely can be accessed in one place using a universal file path.

Once one of the media automation tools imports the file, it will notify Autoscan. Autoscan listens for requests sent by the *Arr stack and in turn notifies Plex that new media is available at the specified location. This greatly reduces the number of API calls to Google Drive since Plex does not perform its default behaviour of scanning the entire folder for new files.
This is particularly useful because Plex is configured to look for new media in the UnionFS mount and does not make any distinction between locally and remotely hosted media. Two things happen after new media has been imported:
- Autoscan is notified and alerts Plex to refresh a specific directory to locate new content.
- Cloudplow runs at a configured interview to check if the local media folder
exceeds a certain file size. Once that file size is reached, it will use
Rclone to move content from the
localdirectory to theremoteone.
Autoscan reduces the amount of API calls made to Google Drive since Plex’s default scanning behaviour when looking for new content does not work with remote mounts. It will rescan the entire library to check for new content and uses more API calls the more media there is.
Cloudplow avoids the limit of how much can be uploaded in one day by uploading in smaller intervals according to threshold. It also has the added benefit of allowing content to be immediately watchable after being downloaded, and provides a seamless viewing experience even if it’s being pushed to the cloud.
Other Tools
These are some nice to haves, but not necessary to how Plex and media management functions.
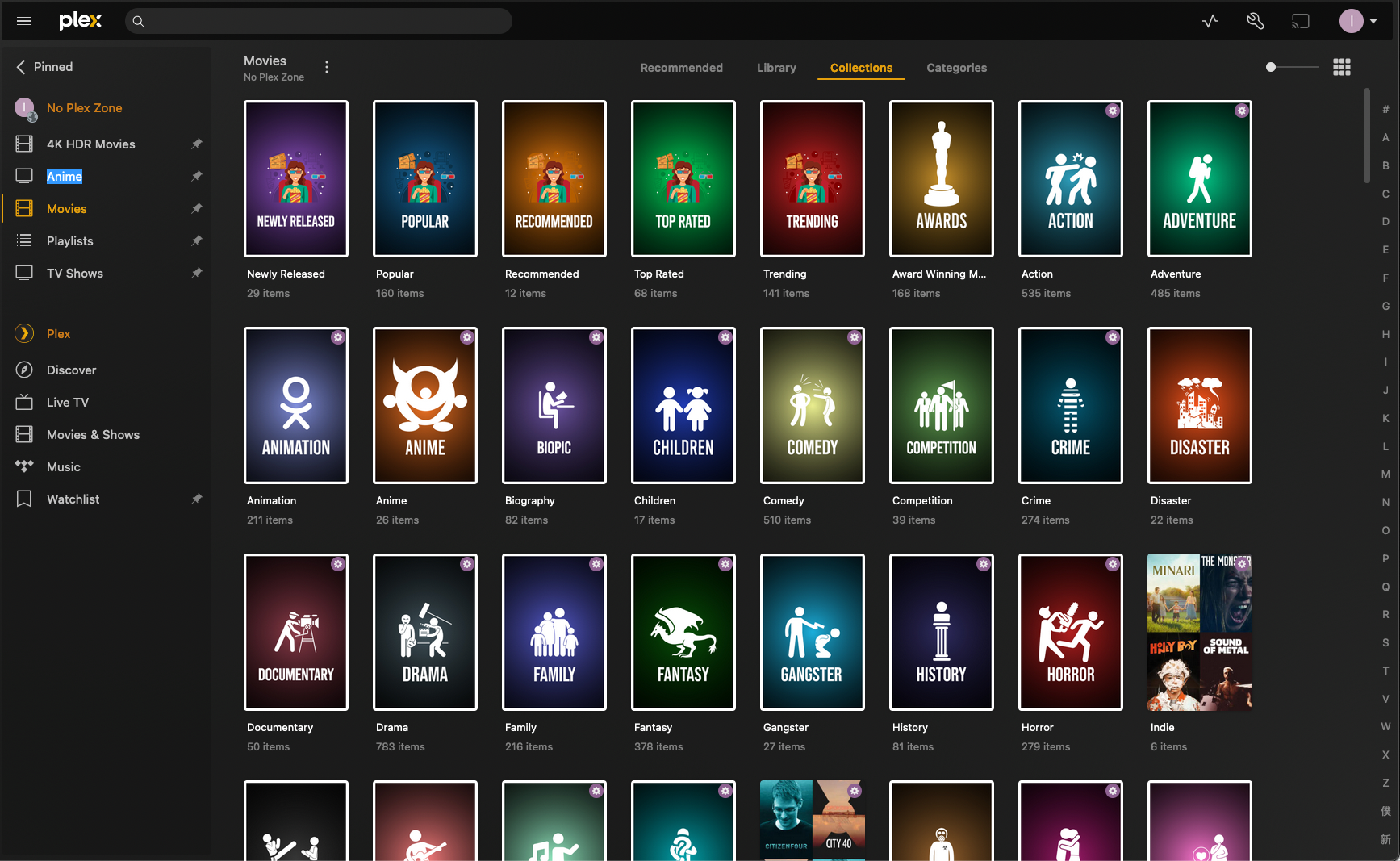
- Plex Meta Manager: Highly configurable tool to create and maintain collections
in Plex. I have not played around with it enough, but so far it dynamically
creates collections for holidays, IMDB lists of top movies, Oscar winners, etc.

Plex Meta Manager - Notifarr: Automatically sync updates to custom profiles from TRaSH-Guides. Additionally notifies on Discord application health issues, newly downloaded content, new application releases, etc.
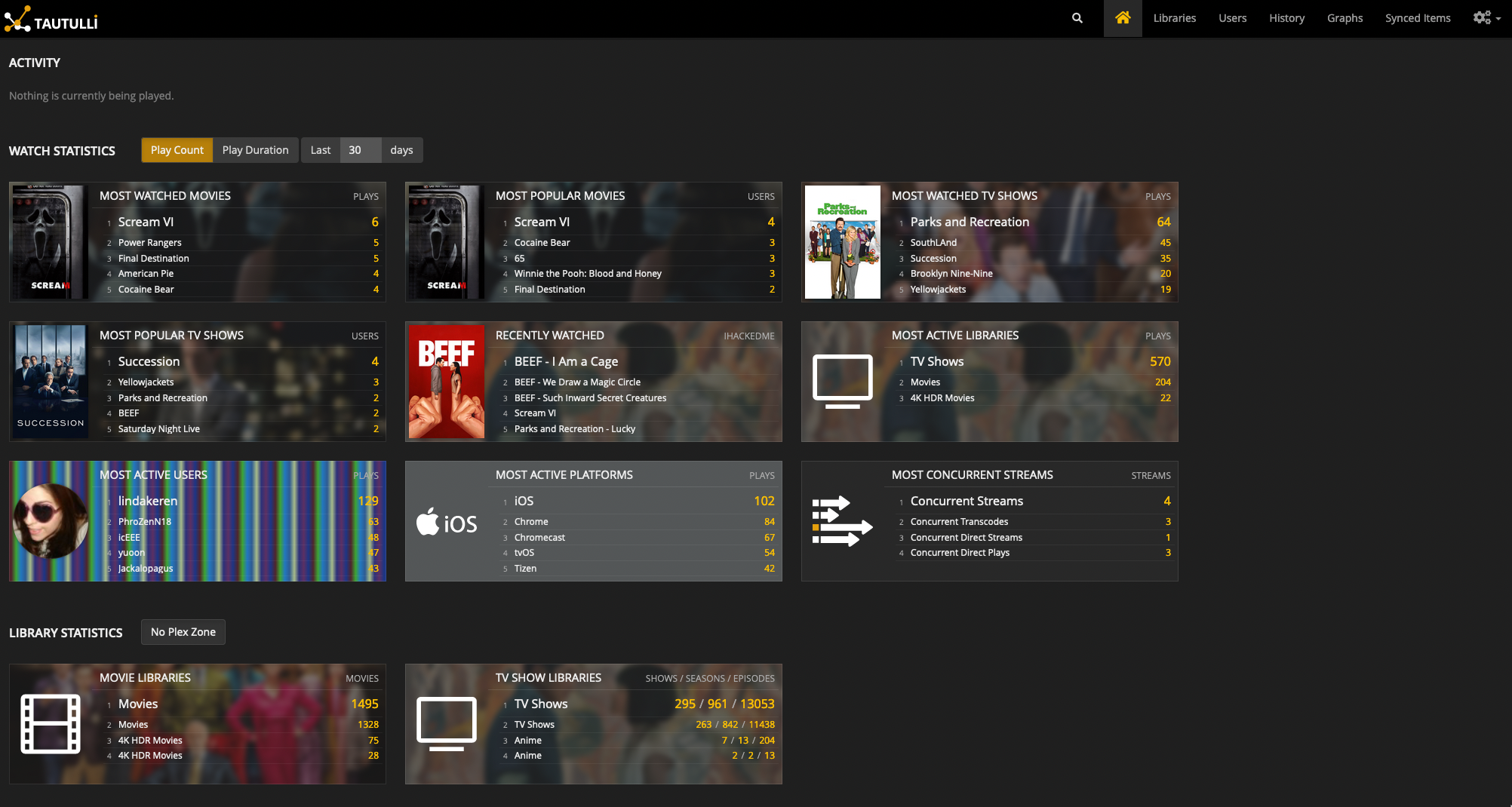
- Tautulli: Plex stats.
Tautulli